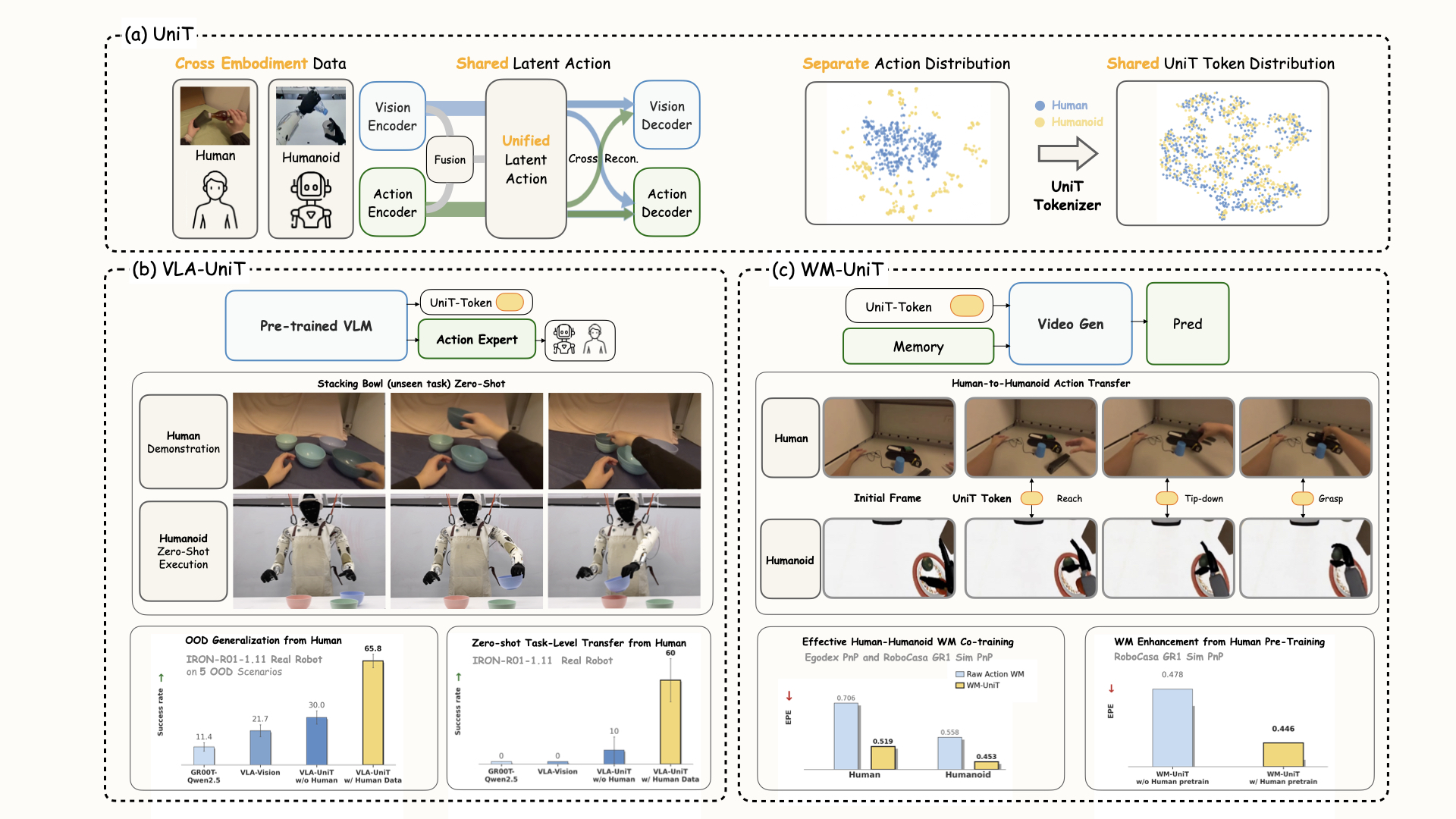
Scaling humanoid foundation models is bottlenecked by scarce robotic data. While massive egocentric human data offers a scalable alternative, bridging the cross-embodiment chasm remains a fundamental challenge. UniT establishes a unified physical language, a single tokenizer that enables zero-shot transfer for both policy learning and world modeling.
Humanoid data is scarce. Human motion is abundant. But the two bodies don't match. To train on both, we need a medium that aligns their action spaces.
The traditional medium is motion retargeting. For each robot, a kinematic solver is hand-engineered to rewrite human joints into robot joints. The action gets converted, but the video does not. As a result, training still pairs human visual observations with robot actions. The mismatch is built into the learning problem from the start. And because every new robot needs its own solver, this pipeline does not scale cleanly.
We want a better medium. It should scale without per-robot engineering. It should also avoid the visual-action mismatch. The answer is a shared latent action space. The question is what that space should look like.
What Should That Latent Look Like?
Prior designs differ in how tightly they align vision and action.
① Single modality.
Action-only tokenizers miss visual grounding. Vision-only tokenizers entangle appearance and waste pose priors.
② Dual modality, loose alignment.
Both modalities are encoded. But the alignment is absent, one-way, or only distributional.
All of them miss the same thing. Vision and action may be brought closer, but they are still modeled as separate spaces. What is missing is a single representation that both modalities truly share.
(a)Action-Only
Action reconstructs itself. No visual grounding. Codes stay embodiment-specific.
(b)Vision-Only
Vision reconstructs itself. Pose priors are ignored. Appearance gets entangled.
(c)Dual, Loose Align.
Each modality reconstructs itself. Alignment is at most distribution-level (dashed). No cross-modal reconstruction between branches.
(d)UniT (Ours)
Cross-reconstruction through one codebook. Every branch's token must decode into both modalities.
vision streamaction stream
Four ways to build a shared latent action space. Only UniT forces vision and action to pass through a single codebook and reconstruct each other. It is the only design where every code is anchored on both sides.
Vision as the Anchor
If we can't align bodies directly, we need an anchor. Vision is the natural candidate. Human and humanoid kinematics may differ, but the physical outcomes of their intents share a consistent visual representation. That is why visual observations can serve as a universal anchor for aligning disparate kinematic spaces.
But vision alone is not enough. Video mixes physical change with appearance factors such as background, lighting, and texture. Action traces have their own noise as well, including embodiment-specific kinematics and sensor jitter. Neither modality is pure signal on its own.
They do, however, describe the same physical event from different sides.
Whatever is coherent across both is physical by construction. Whatever only one side can see is noise.
UniT turns that coherence into the anchor. Vision and action are forced to reconstruct each other through a shared codebook. Only the mutual signal survives. What remains is embodiment-agnostic physical intent. We call it the Unified Latent Action.
Method
UniT: Unified Latent Action Tokenizer via Visual Anchoring
UniT functions as a cross-modal information bottleneck: it concurrently extracts temporal-visual, kinematic, and fused visuo-motor features, and enforces rigorous cross-reconstruction to distill the embodiment-agnostic physical intent.
Architecture of UniT. Cross-embodiment vision pairs (ot, ot+k) and action chunks at:t+k are encoded into vision, action, and fused features via tri-branch encoders. A shared RQ-VAE codebook quantizes all three branches into a unified discrete space. Both vision and action decoders reconstruct from these shared tokens, enforcing cross-reconstruction alignment.
1
Tri-Branch Encoding
Visual branch (IDM on frozen DINOv2 features) captures physical transitions. Action branch encodes embodiment-specific state and action chunks via per-embodiment MLPs. Fusion branch integrates both into a compact visuo-motor representation.
2
Cross-Reconstruction
Every quantized token is decoded by both a visual decoder (FDM) and an action decoder. By forcing kinematic features to reconstruct visual transitions, heterogeneous actions are anchored to their physical consequences. Uncorrelated noise from either domain is discarded.
3
Two Deployment Modes
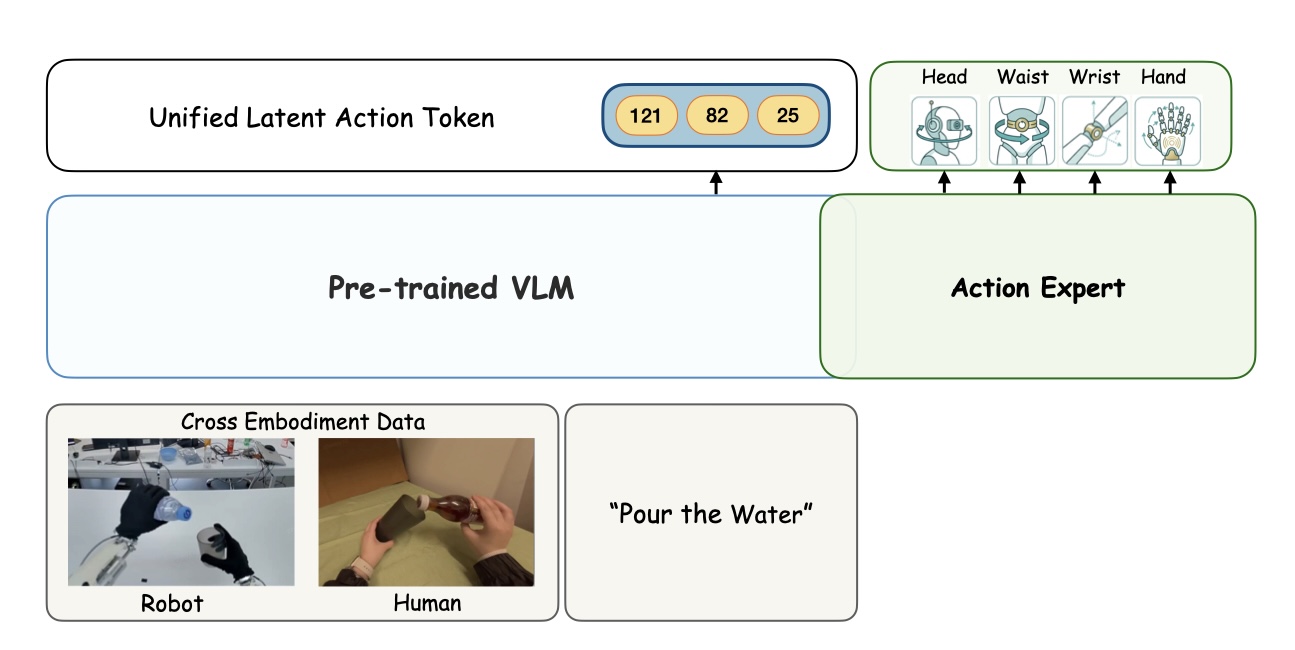
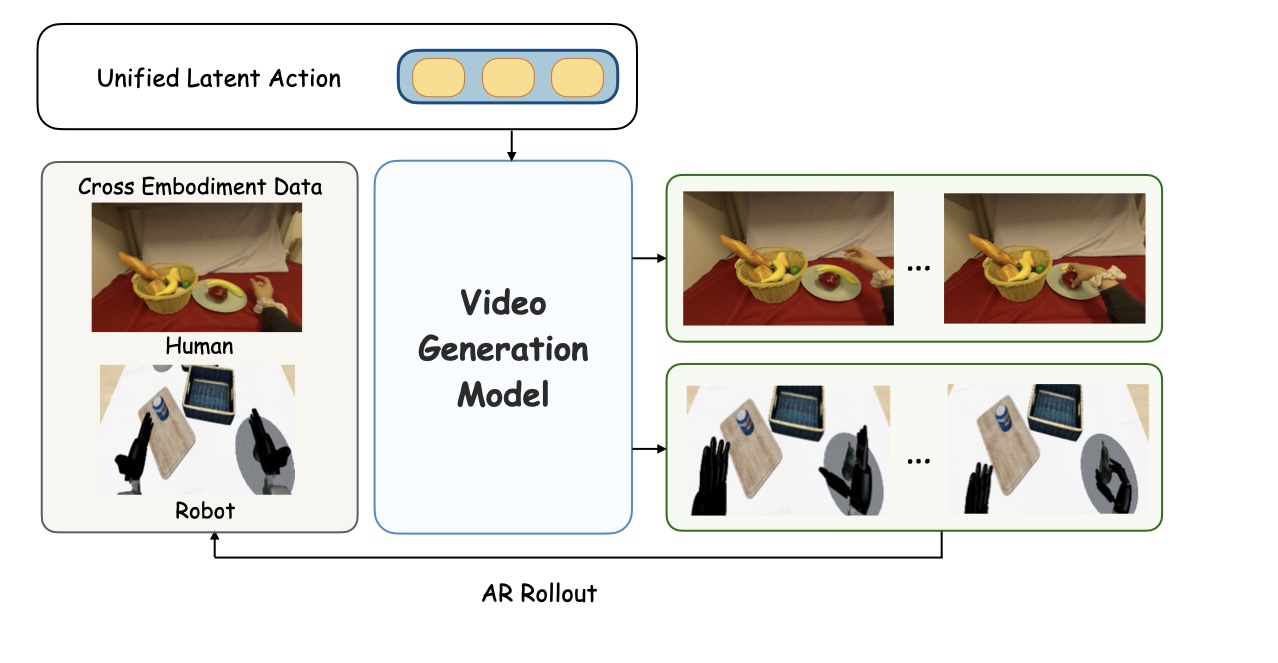
Policy learning: Fusion-branch tokens serve as a structured cross-embodiment prediction target for VLMs (VLA-UniT). World modeling: Continuous action-branch features provide a universal conditioning interface for video generation (WM-UniT).
(a) VLA-UniT. Rather than direct action regression, the VLM predicts Unified Latent Action tokens in the shared space via cross-entropy. A lightweight flow-matching action expert generates embodiment-specific controls from the same vision-language context.(b) WM-UniT. Continuous pre-quantization features from the UniT action branch are projected and injected via cross-attention, providing embodiment-agnostic action conditions for autoregressive video generation.
The Unified Space
Does UniT Actually Create a Shared Manifold?
Before looking at downstream task performance, we verify whether UniT does what it claims: project heterogeneous human and humanoid actions into a shared latent space, and propagate that alignment into the internals of downstream models. We perform t-SNE analysis on samples drawn from the RoboCasa GR1 and EgoDex co-training mixture, at three levels — raw actions vs. UniT token embeddings, VLA vision-language features, and WM cross-attention context embeddings.
Downstream baselines share architectures with our UniT variants but consume raw actions: GR00T-Qwen2.5-FT for policy learning (Qwen2.5-VL backbone with the core language modeling blocks fine-tuned to predict raw actions) and Cosmos Predict 2.5 with raw action conditioning for world modeling. Both baselines are trained on the same human-humanoid mixture.
Representation Alignment
In the raw action space, human and humanoid data form clearly separated clusters reflecting the inherent distribution gap between heterogeneous kinematics. After encoding through UniT, the visual-anchored cross-reconstruction successfully projects disparate action spaces into a shared manifold.
Raw Action Space — separated clusters
Alignment propagates into downstream model internals
Mean-pooled last-layer cross-attention outputs. The vanilla WM exhibits fully disjoint clusters, whereas WM-UniT brings them into a single unified distribution.
Cosmos Predict 2.5 Action-Conditioned — disjoint cross-attention features
UniT tokens not only form a shared cross-embodiment latent space, but also induce two fundamentally different downstream architectures — a VLM for policy learning and a DiT for world modeling — to develop embodiment-agnostic internal representations. This alignment emerges from the tokenizer, providing the structural basis for cross-embodiment transfer.
Downstream Paradigm I
Policy Learning: From Data Efficiency to Zero-Shot Transfer
UniT token prediction gives the VLM a compact, visually-anchored prediction target that encodes physical intent, replacing direct action regression inside the learning loop. A lightweight flow head then decodes the predicted tokens into embodiment-specific actions for execution.
We evaluate VLA-UniT along two axes: efficiency — benchmark performance and sample efficiency on the RoboCasa GR1 simulation benchmark — and human-to-humanoid transfer, which leverages EgoDex human demonstrations to improve policy learning, validated both in simulation and on the real-world IRON-R01-1.11 humanoid (50-dimensional action space).
Efficiency
We evaluate VLA-UniT on the RoboCasa GR1 simulation benchmark along two protocols: full-data benchmark performance against a broad set of policy baselines, and reduced-data sample efficiency against the matched GR00T architecture. Both probe whether compact, visually-anchored token prediction extracts task-relevant intent more effectively than direct action regression.
VLA-UniT reaches 66.7% overall success rate on the full-data RoboCasa GR1 benchmark, balanced across Pick & Place (67.3%) and Articulated (64.7%). It surpasses the previous best FLARE by +11.7%, and the GR00T baseline — which shares the same architecture without UniT token prediction — by +18.9%.
With only 10% of the training data (100 trajectories per task), VLA-UniT (45.5%) already approaches the GR00T baseline trained on full data (47.8%) — roughly a 10× reduction in data requirements. Operating in a structured discrete latent space, rather than regressing raw actions, lets the VLM extract task-relevant intent more efficiently from limited demonstrations.
Autonomous 4x
Pick up the cup, place it into the drawer and close the drawer
Autonomous 4x
Pick up the milk, place it into the microwave and close the microwave
Autonomous 4x
Pick up the wine, place it into the cabinet and close the cabinet
Autonomous 4x
Pick the bell pepper from the tray and place it in the tiered shelf
Autonomous 4x
Pick the can from the plate and place it in the cardboard box
Autonomous 4x
Pick the cupcake from the cutting board and place it in the tiered basket
Human-to-Humanoid Transfer
Human Data Unlocks Generalization
Under the few-shot regime in simulation, we co-train VLA-UniT on robot data and EgoDex's basic_pick_place human demonstrations (27,419 trajectories), then fine-tune on robot data alone — testing whether UniT's shared latent space lets humanoid policy learning actually draw on human data.
Incorporating human data brings consistent improvements across both in-domain and all three OOD categories. The in-domain average rises from 45.5% → 50.0%, with the largest gain in Pick & Place (41.7% → 49.4%) — exactly the setting that corresponds to the EgoDex domain — and the OOD average rises from 34.7% → 38.5%.
Autonomous 4x
Pick the bell pepper from the cutting board and place it in the basket * bell pepper appears with unseen texture and color variant
Autonomous 4x
Pick the croissant from the cutting board and place it in the cardboard box * croissant appears with unseen visual appearance
Autonomous 4x
Pick up the wine, place it into the drawer and close the drawer * wine × drawer pairing never seen during training
Autonomous 4x
Pick the sweet potato from the placemat and place it in the pot* sweet potato × pot pairing never seen during training
Autonomous 4x
Pick the rubix cube from the placemat and place it in the pan * rubix cube is an entirely unseen object category
Autonomous 4x
Pick the fish from the placemat and place it in the pot * fish is an entirely unseen object category
Human Data Drives Real-World Performance
We next deploy VLA-UniT on the real-world IRON-R01-1.11 humanoid (50-dimensional action space) to check whether the simulation gains carry over to physical execution. Two tasks are evaluated: Pick & Place (analogous to EgoDex basic_pick_place) and Pouring (analogous to pour, requiring bimanual coordination).
Generalization is probed along five OOD axes — Geometry, Distractor, Target, Background, and Combinational. The first four are set up so that robot data provide only partial coverage, while human demonstrations introduce the complementary variation; the Combinational axis tests instruction-based disambiguation among multiple objects seen during training.
With robot data alone, VLA-UniT already substantially outperforms the GR00T baseline on both tasks: Pick & Place 70% vs. 30%, Pouring 35% vs. 5%. Adding EgoDex human co-training lifts them further to 78% and 75% — the gain is particularly pronounced on Pouring, where coordinated dual-arm control is rare in the limited robot set but abundant in human demonstrations.
Autonomous 4x
Put the banana in the box
Autonomous 4x
Put the bowl in the box
Autonomous 4x
Pour contents from the bottle into the cup
Autonomous 4x
Pour contents from the bottle into the cup
Autonomous 4x
Pour contents from the bottle into the cup
Human co-training consistently improves all five OOD axes. Geometry (23.3% → 63.3%) and Distractor (26.7% → 60.0%) show the largest gains — exactly where human videos introduce novel object shapes and visual clutter absent from the limited robot set. The Combinational axis, which tests instruction-based disambiguation, also jumps from 10% → 70%, suggesting that the broader interaction diversity from human co-training also strengthens compositional generalization.
Training Coverage
1Robot Demo
Limited, fixed object set
Put the banana in the box
Put the bowl in the box
2Human Demo
Diverse objects with varied geometries
Pick and place the bread* varied geometry, similar grasp
Pick and place the cup* varied geometry, similar grasp
UniT Transfer
Zero-Shot Execution
3OOD: Geometry
Autonomous 4x
Put the bread in the box * unseen geometry; grasp pattern from human data
Autonomous 4x
Put the cup in the box * unseen geometry; grasp pattern from human data
Training Coverage
1Robot Demo
Limited, single-object scenes
Put the banana in the box
Put the bowl in the box
2Human Demo
Diverse, cluttered multi-object scenes
Pick and place the banana * varied surrounding distractors
Pick and place the bowl * varied surrounding distractors
UniT Transfer
Zero-Shot Execution
3OOD: Distractor
Autonomous 4x
Pick and place the banana * unseen distractors; absent in robot data
Autonomous 4x
Pick and place the bowl * unseen distractors; absent in robot data
Training Coverage
1Robot Demo
Limited, fixed target (box only)
Put the banana in the box
Put the bowl in the box
2Human Demo
Diverse target receptacles
Place the object in the blue bowl* varied target receptacle
Place the object on the red plate* varied target receptacle
UniT Transfer
Zero-Shot Execution
3OOD: Target
Autonomous 4x
Put the banana in the blue bowl* unseen target; only box in robot data
Autonomous 4x
Put the bowl on the red plate* unseen target; only box in robot data
Training Coverage
1Robot Demo
Limited, single-scene collection
Put the banana in the box
Put the bowl in the box
2Human Demo
Diverse scenes and backdrops
Pick up the banana * varied backdrop setting
Pick up the bowl * varied backdrop setting
UniT Transfer
Zero-Shot Execution
3OOD: Background
Autonomous 4x
Put the banana in the box * unseen backdrop; single scene in robot data
Autonomous 4x
Put the bowl in the box * unseen backdrop; single scene in robot data
Training Coverage
1Robot Demo
Limited, fixed object × scene
Put the bowl in the box
Zero-Shot
Combinational Execution
2Unseen Setting
Autonomous 4x
Put the cup in the box * unseen object × scene combination
3Unseen Setting
Autonomous 4x
Put the bowl in the box * unseen object × scene combination
Human Data Enables Zero-Shot Task Transfer
We finally evaluate on a stacking task that is not covered by any robot training demonstration: the robot set only includes pick-and-place of individual bowls, while EgoDex human videos do contain stacking sequences performed with view switching and upper-body coordination. This isolates whether VLA-UniT can carry a new task over from human data alone.
Human Demonstration
Stack the green bowl on the red bowl
Zero-Shot
Robot Zero-Shot Execution
Autonomous 4x
Stack the blue bowl on the red bowl
Human Demonstration
Unstack the dark green bowl from the purple bowl
Zero-Shot
Robot Zero-Shot Execution
Autonomous 4x
Unstack the blue bowl from the red bowl
Emergent Coordination. With human co-training, VLA-UniT reaches 60%, transferring not just task semantics but fine-grained coordination patterns: the humanoid exhibited unprogrammed waist rotation and head turning that directly mirror human demonstrations.
Downstream Paradigm II
World Modeling: From Controllability to Human-Humanoid Imagination
Action-conditioned world models normally take in embodiment-specific raw actions — humanoid joints, wrist poses, and human hand trajectories each living in their own action vocabulary. WM-UniT replaces this interface with UniT's continuous pre-quantization features as a unified conditioning signal, built on the Cosmos Predict 2.5 action-conditioned video backbone and trained with flow matching.
We examine WM-UniT along two axes: controllable generation — on a single embodiment (DROID) and under human-humanoid co-training — and human-humanoid transfer, via both human pre-training and direct cross-embodiment conditioning.
Controllability
Single-Embodiment Controllability
We start in the simplest setting: a single embodiment, DROID, where raw actions already share a consistent kinematic convention. The question is whether UniT conditioning still improves controllability here. We compare three interfaces under an identical Cosmos Predict 2.5 backbone — Raw Action, WM-Action (action-only latent tokenization), and WM-UniT.
WM-UniT wins on EPE — the most direct indicator of action controllability — while WM-Action does not yield a similarly reliable gain, indicating that latent tokenization alone is insufficient without visual anchoring.
Method
PSNR ↑
SSIM ↑
LPIPS ↓
FVD ↓
EPE ↓
Raw Action
21.02
0.820
0.097
76.38
0.2662
WM-Action
20.86
0.819
0.102
80.30
0.2593
WM-UniT
21.32
0.823
0.095
76.44
0.2588
10x Rollout
10x Rollout
10x Rollout
10x Rollout
Human-Humanoid Controllability
We next jointly train a single world model on EgoDex human demonstrations and RoboCasa-GR1 humanoid demonstrations. The question is whether a unified conditioning interface still holds up when the training signal spans two heterogeneous embodiments in the same model.
WM-UniT consistently outperforms Raw Action on both subsets, with the clearest gain in controllability (EPE). Together with the aligned cross-embodiment context embeddings from our representation analysis, this indicates that UniT provides a shared conditioning space that lets the world model co-train on human and humanoid data without collapsing into embodiment-specific dynamics.
Dataset
Method
PSNR ↑
SSIM ↑
LPIPS ↓
FVD ↓
EPE ↓
EgoDex
Raw Action
24.84
0.800
0.164
171.37
0.706
WM-UniT
28.06
0.858
0.086
130.87
0.519
RoboCasa-GR1
Raw Action
13.45
0.590
0.259
237.13
0.558
WM-UniT
17.66
0.718
0.142
166.50
0.453
Human (EgoDex)
5-Step Rollout
Robot (RoboCasa-GR1)
10-Step Rollout
Human (EgoDex)
4-Step Rollout
Robot (RoboCasa-GR1)
10-Step Rollout
Human (EgoDex)
10-Step Rollout
Robot (RoboCasa-GR1)
10-Step Rollout
Human (EgoDex)
10-Step Rollout
Robot (RoboCasa-GR1)
7-Step Rollout
Human-Humanoid Transfer
Human Pre-Training Improves Robot World Modeling
Co-training shows that a shared conditioning space exists; pre-training asks whether physical dynamics learned from human data can actually be transferred to humanoid prediction. We pre-train WM-UniT on EgoDex's 27,419 basic_pick_place human trajectories, then fine-tune on RoboCasa-GR1 pick-and-place data.
Human pre-training brings consistent gains across all metrics, with the most meaningful improvement reflected in controllability. The dynamics learned from human data remain usable after transfer to humanoid prediction, rather than being tied to human-specific kinematics — UniT provides a transferable dynamics interface for world modeling.
Configuration
PSNR ↑
SSIM ↑
LPIPS ↓
FVD ↓
EPE ↓
WM-UniT w/o Human Pre-training
16.34
0.678
0.168
180.51
0.478
WM-UniT (Full)
18.06
0.713
0.135
153.31
0.446
10-Step Rollout
10-Step Rollout
9-Step Rollout
10-Step Rollout
Human-Humanoid Conditioning Consistency
Beyond co-training and pre-training, we directly test whether UniT tokens from one embodiment can condition video generation for the other — without any domain-specific adaptation.
The setup is straightforward. We condition the world model with the per-frame action sequence of a source demonstration, apply it on top of the target embodiment's start frame, and let the model autoregressively generate the full video. Both directions are evaluated — Human→Humanoid and Humanoid→Human — and we compare WM-UniT against Raw Action conditioning.
To quantify these generations, we use Gemini-3-Pro as an automated judge and score three dimensions on a 1–5 scale: Semantic consistency (whether the intended action is preserved), Temporal consistency (whether motion timing and sequencing match, including non-monotonic trajectories such as reach-then-retract), and Geometric consistency (whether spatial trajectories and pose details are faithful).
Direction
Method
Semantic ↑
Temporal ↑
Geometric ↑
Overall ↑
Robot → Human
Raw Action
2.96
3.12
2.74
2.92
WM-UniT
3.91
3.98
3.66
3.84
Human → Robot
Raw Action
2.98
3.16
2.72
2.95
WM-UniT
3.28
3.43
3.09
3.27
WM-UniT consistently outperforms Raw Action in semantic, temporal, and geometric consistency (3.28 / 3.43 / 3.09 vs. 2.98 / 3.16 / 2.72), confirming that UniT preserves fine-grained action intent across embodiments.
Human Demonstration
Reference
Human→Humanoid Action Cond.
Start Frame
Initial Frame
Generated Humanoid · 5-Step Rollout
WM-UniT
Raw Action
Human Demonstration
Reference
Human→Humanoid Action Cond.
Start Frame
Initial Frame
Generated Humanoid · 5-Step Rollout
WM-UniT
Raw Action
Human Demonstration
Reference
Human→Humanoid Action Cond.
Start Frame
Initial Frame
Generated Humanoid · 5-Step Rollout
WM-UniT
Raw Action
Human Demonstration
Reference
Human→Humanoid Action Cond.
Start Frame
Initial Frame
Generated Humanoid · 5-Step Rollout
WM-UniT
Raw Action
WM-UniT achieves stronger consistency across all three dimensions (3.91 / 3.98 / 3.66 vs. 2.96 / 3.12 / 2.74), with the largest gain in geometric fidelity.
Robot Demonstration
Reference
Humanoid→Human Action Cond.
Start Frame
Initial Frame
Generated Human · 5-Step Rollout
WM-UniT
Raw Action
Robot Demonstration
Reference
Humanoid→Human Action Cond.
Start Frame
Initial Frame
Generated Human · 5-Step Rollout
WM-UniT
Raw Action
Robot Demonstration
Reference
Humanoid→Human Action Cond.
Start Frame
Initial Frame
Generated Human · 5-Step Rollout
WM-UniT
Raw Action
Robot Demonstration
Reference
Humanoid→Human Action Cond.
Start Frame
Initial Frame
Generated Human · 5-Step Rollout
WM-UniT
Raw Action
Analysis
Every Design Choice Matters
UniT's design rests on two claims: (1) both vision and action are needed — action-only methods suffer cross-embodiment distribution misalignment without visual grounding, while vision-only methods entangle low-level appearance and miss fine-grained motor detail; and (2) the two modalities must be explicitly aligned through cross-reconstruction, rather than treated as disconnected vocabularies.
We validate both claims under the human-humanoid co-training setup (EgoDex + RoboCasa-GR1 pre-train, RoboCasa-GR1 fine-tune), where the tokenizer's ability to bridge embodiments is directly tested.
VLA-UniT reaches an OOD average of 49.9%, consistently outperforming both single-modality variants: VLA-Vision (45.2%) provides a transferable visual signal but misses fine-grained motor detail, while VLA-Action (42.1%) captures motor intent but struggles with the cross-embodiment distribution gap without visual grounding. Removing cross-reconstruction drops performance further to 30.3% — below both single-modality variants despite using both inputs — indicating that multi-modal input alone does not guarantee alignment. Explicit cross-reconstruction closes that gap with a +19.6% lift.
Cross-Reconstruction Is Essential. Having both modalities is not enough; only explicit cross-reconstruction turns them into a coherent shared vocabulary that bridges human and humanoid.
On in-domain performance we further include VLA-Villa, which uses unidirectional vision-to-action (V2A) reconstruction instead of UniT's bidirectional cross-reconstruction. VLA-UniT (66.8%) consistently outperforms VLA-Villa (63.1%), confirming that bidirectional alignment is more effective than unidirectional alternatives for producing aligned cross-embodiment tokens.
Bidirectional > Unidirectional. Going both ways — vision predicts action and action predicts vision — is what produces tokens that actually transfer across embodiments.
Robustness
Noise Robustness: Visual Anchoring as a Denoiser
In-the-wild human motion capture data inevitably contains noise from sensor jitter and annotation artifacts. We test whether UniT's cross-reconstruction — which grounds actions in visual transitions — provides implicit denoising by encoding and decoding perturbed action signals.
Gaussian noise of intensity σ (normalized by the global action standard deviation) is injected into EgoDex action trajectories, and reconstruction quality is measured by MSE against the clean signal. We compare UniT against two action-only tokenizers: FAST, a frequency-based BPE action tokenizer, and Action Tokenizer, which uses the same RQ-VAE architecture as UniT but is trained on action data alone. Drag the slider to vary σ.
Drag to adjust noise level
00.10.20.30.5
UniT vision + action
1.0×
Action-Only same arch, no vision
1.0×
FAST frequency BPE
1.0×
Visual grounding filters noise. At σ=0.2, FAST degrades by 10.7×, the action-only tokenizer by 2.7×, and UniT by only 1.7×. The gap confirms that visual grounding regularizes the latent space, filtering out kinematic noise that lacks visual correspondence.
Looking Forward
Toward Scalable Embodied Intelligence
We presented UniT, a visual-anchored latent action tokenizer that projects heterogeneous human and humanoid data into a shared discrete space through tri-branch cross-reconstruction. Deployed as VLA-UniT and WM-UniT, it enables consistent human-to-humanoid OOD transfer in both simulation and the real world, zero-shot task transfer with emergent upper-body coordination, and cross-embodiment dynamics transfer for world modeling. Ablations confirm that having both modalities is not enough on its own. A shared vocabulary only emerges when the two are explicitly forced to reconstruct each other.
With this shared space now in place, the natural question is how far it can scale. UniT's visual branch encodes physical transitions from observations alone, without paired action labels, so the shared space is readily extensible to video sources that never came with motor annotations, including the vast reservoirs of internet and egocentric video. And because alignment in UniT is entirely data-driven, even diverse human motion capture can enter the same space directly, without per-robot retargeting. Full-body coordination and dexterous control, in all the variety already recorded, can keep pouring into one latent vocabulary.
Beyond what can enter this shared space, there is the question of what can happen inside it. The same vocabulary is already spoken by both policies and world models, so a policy can propose latent actions that a world model simulates into visual consequences, and those imagined rollouts can feed back as reward signals for reinforcement learning or as search targets for test-time planning, all within one shared space. UniT has so far shown this space as a substrate for transfer. Turning it into a substrate for closed-loop embodied reasoning is what we find most compelling to explore next.